首页 > 深度学习 > 正文
原创文章,转载请注明出处!
本文链接:http://daiwk.github.io/posts/dl-match-for-search-recommendation-traditional.html
match for search recommendation(传统部分)
标签:match, search, recommend, lihang, sigir18, www18
2018-09-09
这里讲传统部分,深度学习部分见:https://daiwk.github.io/posts/dl-match-for-search-recommendation.html
概述
搜索领域的传统匹配模型
使用机器翻译匹配
Statistical Machine Translation (SMT)
Word-based Model: IBM Model One
使用Word-based Translation Models进行匹配
使用Phrase-based translation models进行匹配
在latent space中匹配
Partial Least Square (PLS)
Regularized Mapping to Latent Space(RMLS)
推荐领域的传统匹配模型
Collaborative Filtering Models
Memory-based CF
Model-based CF
Item-based CF in Latent Space
Fusing User-based and Item-based CF in Latent Space
MF
FISM
SVD++
Generic Feature-based Models
Factorization Machine
Rendle, ICDM’10
FM使得矩阵分解更容易加特征了,所以,可以模仿以下模型的效果:
MF,SVD++,timeSVD(Koren,KDD’09),PIFT(Rendle,WSDM’10)etc.
例如:
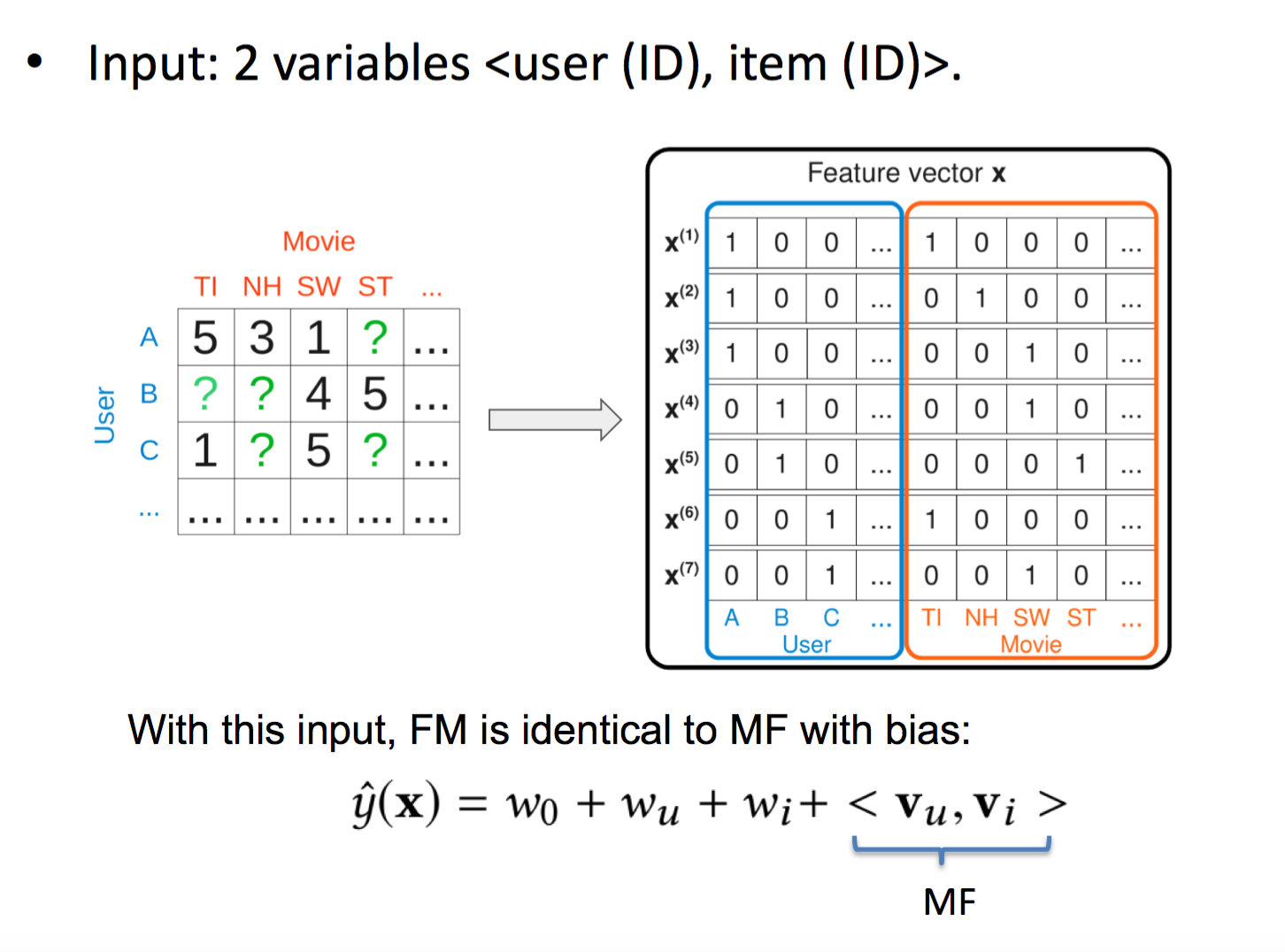
当xxxx时,FM和MF+bias是等价的:
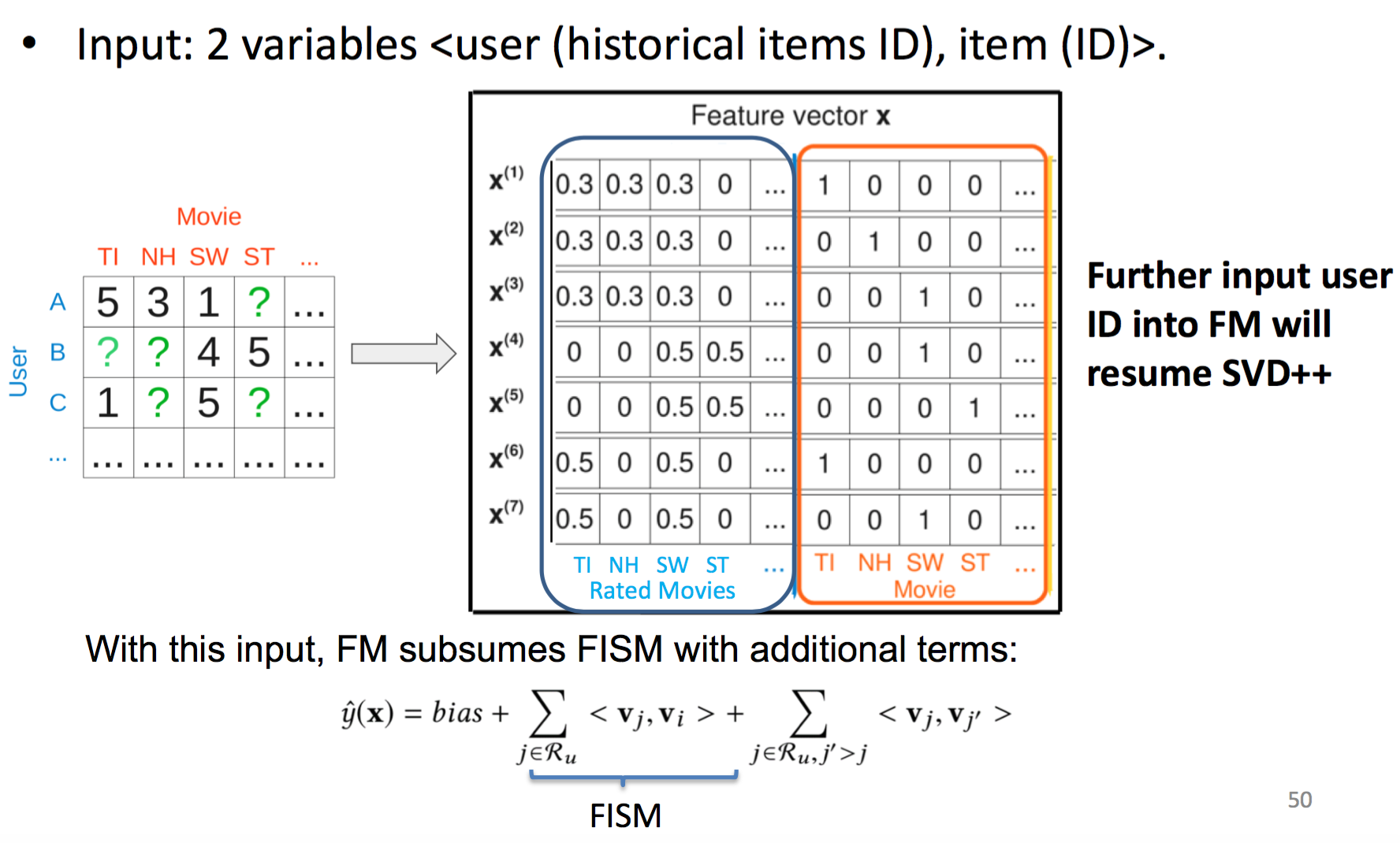
当xxxx时,FM和SVD++是等价的:
隐式反馈vs 显式反馈
top-k 推荐
原创文章,转载请注明出处!
本文链接:http://daiwk.github.io/posts/dl-match-for-search-recommendation-traditional.html
comment here..