dl中的normalization
标签:normalization, bn, ln目录
batch normalization
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
参考http://blog.csdn.net/hjimce/article/details/50866313
主要有四个好处:
- 快速训练收敛的特性。可以选择比较大的初始学习率,让你的训练速度飙涨。以前还需要慢慢调整学习率,甚至在网络训练到一半的时候,还需要想着学习率进一步调小的比例选择多少比较合适。现在我们可以采用初始很大的学习率,然后学习率的衰减速度也很大,因为这个算法收敛很快。即使你选择了较小的学习率,也比以前的收敛速度快。
- 提高网络泛化能力的特性。不用去理会过拟合中drop out、L2正则项参数的选择问题。移除这两项了参数,或者可以选择更小的L2正则约束参数了。
- 本身就是一个归一化网络层。不需要使用使用局部响应归一化层(Alexnet网络用到的方法)。
- 可以把训练数据彻底打乱。防止每批训练的时候,某一个样本都经常被挑选到。
一般地,在神经网络训练开始前,都要对输入数据做一个归一化处理,原因如下:
- 神经网络学习过程本质就是为了学习数据分布,一旦训练数据与测试数据的分布不同,那么网络的泛化能力也大大降低
- 一旦每批训练数据的分布各不相同(batch 梯度下降),那么网络就要在每次迭代都去学习适应不同的分布,这样将会大大降低网络的训练速度。
参考https://blog.csdn.net/qq_25737169/article/details/79048516
layer normalization
参考知乎的讨论:
https://www.zhihu.com/question/59728870
https://www.zhihu.com/question/48820040
参考:
https://skyhigh233.com/blog/2017/07/21/norm/
直观区别:
- bn是“竖”着来的,对于某一个神经元,会拿整个batch所有样本的值来做归一化。
- ln是“横”着来的,对一个样本,在不同的神经间做归一化。
好处:
- 它的training和inference没有区别,只需要对当前隐藏层计算mean和variance就行
- 不需要保存每层的moving average mean and variance
- 不受batch size的限制,可以通过online learning的方式一条一条地输入训练数据
- LN可以方便的在RNN中使用
- LN增加了gain和bias作为学习的参数,
\(\mu\)和\(\sigma\)分别是该layer的隐层维度的均值和方差
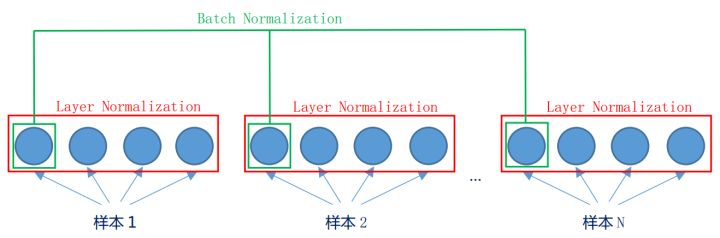
LayerNorm是Batch Normalization的一个变体,BN针对一个minibatch的输入样本,计算均值和方差,基于计算的均值和方差来对某一层神经网络的输入X中每一个case进行归一化操作。但BN有两个明显不足:1、高度依赖于mini-batch的大小,实际使用中会对mini-Batch大小进行约束,不适合类似在线学习(mini-batch为1)情况;2、不适用于RNN网络中normalize操作:BN实际使用时需要计算并且保存某一层神经网络mini-batch的均值和方差等统计信息,对于对一个固定深度的前向神经网络(DNN,CNN)使用BN,很方便;但对于RNN来说,sequence的长度是不一致的,换句话说RNN的深度不是固定的,不同的time-step需要保存不同的statics特征,可能存在一个特殊sequence比其的sequence长很多,这样training时,计算很麻烦。但LN可以有效解决上面这两个问题。LN中同层神经元输入拥有相同的均值和方差,不同的输入样本有不同的均值和方差;而BN中则针对不同神经元输入计算均值和方差,同一个minibatch中的输入拥有相同的均值和方差。因此,LN不依赖于mini-batch的大小和输入sequence的深度,因此可以用于bath-size为1和RNN中对边长的输入sequence的normalize操作。参考深度学习加速器Layer Normalization-LN
原创文章,转载请注明出处!
本文链接:http://daiwk.github.io/posts/dl-normalization.html