首页 > 自然语言处理 > 正文
原创文章,转载请注明出处!
本文链接:http://daiwk.github.io/posts/nlp-tagspaces.html
tagspace
标签:tagspace
2018-01-02
目录
概述
#TagSpace: Semantic Embeddings from Hashtags
https://research.fb.com/publications/tagspace-semantic-embeddings-from-hashtags/
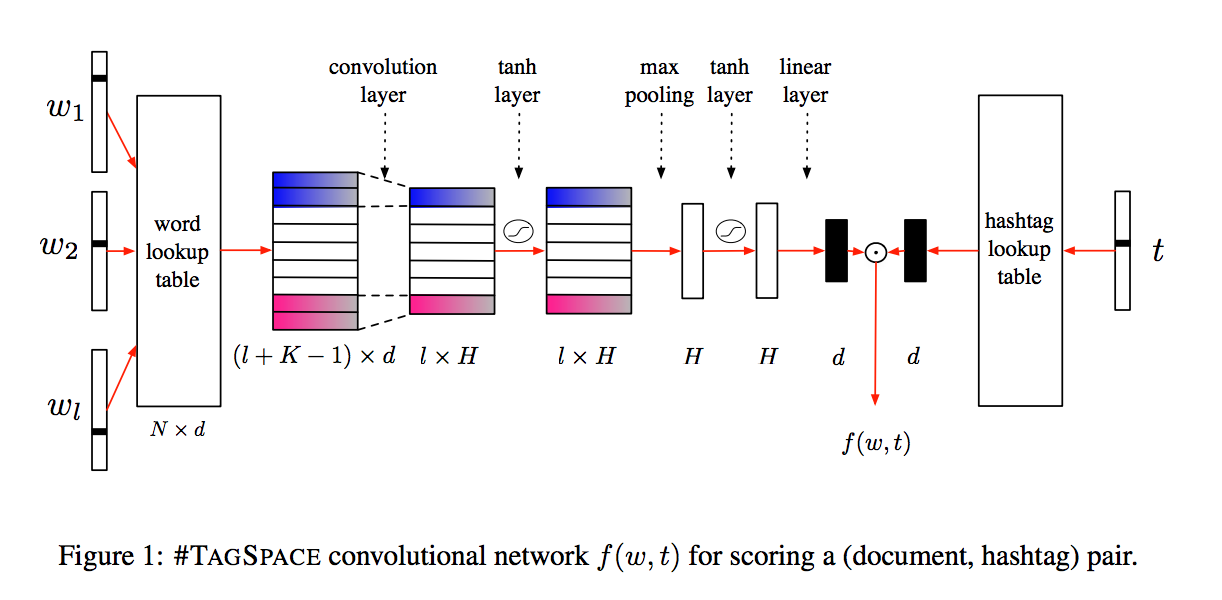
假设一句话有l个词,总词典大小是N,那么大的emb矩阵就是Nxd,而对于这句话来讲,就是一个lxd的矩阵,然后用same padding,并用1D卷积,详细地说,就是先padding成一个(l+K-1)xd的矩阵,然后有H个Kxd的卷积核,这样得到的结果就是一个(l+K-1-K+1)x(d-d+1)xH=lx1xH=lxH的矩阵了,之所以叫same padding,就是因为一开始的第一维是l,最终的第一维仍是l。
对于maxpooling来说,输入是lxH,按照论文和图中的,应该是l个数取max,得到1xH,但下面的tf的实现,好像不是这样的呢。。。paddle的实现用的是https://daiwk.github.io/posts/nlp-nmt.html#8-%E5%85%B6%E4%BB%96这个的sequence_conv_pool函数,实现参考
参考tf代码https://github.com/flrngel/TagSpace-tensorflow/blob/master/model.py
doc_embed = tflearn.embedding(doc, input_dim=N, output_dim=d)
self.lt_embed = lt_embed = tf.Variable(tf.random_normal([tN, d], stddev=0.1)) # 在卷积这步这个变量没啥用
net = tflearn.conv_1d(doc_embed, H, K, activation='tanh')# conv_1d默认是same padding,卷积核是Kxd,有H个卷积核,输出是(None,l,d)
net = tflearn.max_pool_1d(net, K) # max_pool_1d默认也是same pooling,输出是(None,xxx,H)
## maybe上面那行应该改成tensorflow.keras.layers.GlobalMaxPooling1D(net)# 输出就是(None,H)啦?
net = tflearn.tanh(net)
self.logit = logit = tflearn.fully_connected(net, d, activation=None)
参考paddle代码:https://github.com/PaddlePaddle/models/blob/develop/fluid/PaddleRec/tagspace/net.py
text_emb = nn.embedding(
input=text, size=[vocab_text_size, emb_dim], param_attr="text_emb")
pos_tag_emb = nn.embedding(
input=pos_tag, size=[vocab_tag_size, emb_dim], param_attr="tag_emb")
neg_tag_emb = nn.embedding(
input=neg_tag, size=[vocab_tag_size, emb_dim], param_attr="tag_emb")
conv_1d = fluid.nets.sequence_conv_pool(
input=text_emb,
num_filters=hid_dim,
filter_size=win_size,
act="tanh",
pool_type="max",
param_attr="cnn")
text_hid = fluid.layers.fc(input=conv_1d, size=emb_dim, param_attr="text_hid")
cos_pos = nn.cos_sim(pos_tag_emb, text_hid)
原创文章,转载请注明出处!
本文链接:http://daiwk.github.io/posts/nlp-tagspaces.html
comment here..