分布式强化学习框架
标签:分布式强化学习, A3C, ape-x, rudder, impala, rlpyt, open spiel, rainbow, ppo目录
1. 概述
略 大部分在ray中都已经有啦,还有openai的baselines
https://github.com/ray-project/ray/blob/master/doc/source/rllib-algorithms.rst
https://github.com/openai/baselines
2. A3C
参考https://blog.csdn.net/jinzhuojun/article/details/72851548
ICML2016,提出了Asynchronous Methods for Deep Reinforcement Learning,即A3C(asynchronous advantage actor-critic)算法。
A3C不仅适用于离散也适用于连续动作空间的控制问题。DRL领域也确实有很成功的分布式机器学习系统,比如Google的Gorila。这篇文章另辟蹊径,发明了“平民版”的DRL算法,而且效果还不比前者差。
传统经验认为,online的RL算法在和DNN简单结合后会不稳定。主要原因是观察数据往往波动很大且前后sample相互关联。像Neural fitted Q iteration和TRPO方法通过将经验数据batch,或者像DQN中通过experience replay memory对之随机采样,这些方法有效解决了前面所说的两个问题,但是也将算法限定在了off-policy方法中。
而A3C是通过创建多个agent,在多个环境实例中并行且异步的执行和学习。于是,在DNN下,解锁了一大批online/offline的RL算法(如Sarsa, AC, Q-learning)。A3C不那么依赖于GPU或大型分布式系统,可以跑在一个多核CPU上。
将value function的估计作为baseline可以使得PG方法有更低的variance。这种设定下,就有了所谓的A - advantage,即,\(R_t−b_t(s_t)\),即\(A(s_t,s_t)=Q(a_t,s_t)−V(s_t)\),就是advantage function的估计。
将one-step Sarsa, one-step Q-learning, n-step Q-learning和advantage AC扩展至多线程异步架构。
注意,该框架是具有通用性的,例如,AC是on-policy的policy搜索方法,而Q-learning是off-policy value-based方法。
每个线程都有agent运行在环境的拷贝中,每一步生成一个参数的梯度,多个线程的这些梯度累加起来,一定步数后一起更新共享参数。
优点:
- 它运行在单个机器的多个CPU线程上,而非使用parameter server的分布式系统,这样就可以避免通信开销和利用lock-free的高效数据同步方法(Hogwild!方法)【2011年的Hogwild ! : A Lock-Free Approach to Parallelizing Stochastic Gradient Descent是一种并行SGD方法。该方法在多个CPU时间进行并行。处理器通过共享内存来访问参数,并且这些参数不进行加锁。它为每一个cpu分配不重叠的一部分参数(分配互斥),每个cpu只更新其负责的参数。该方法只适合处理数据特征是稀疏的。该方法几乎可以达到一个最优的收敛速度,因为cpu之间不会进行相同信息重写。】
- 多个并行的actor可以有助于exploration。在不同线程上使用不同的探索策略,使得经验数据在时间上的相关性很小。这样不需要DQN中的experience replay也可以起到稳定学习过程的作用,意味着学习过程可以是on-policy的,所以可以使用on-policy方法(如Sarsa),且能保证稳定。
A3C和DDPG类似,通过DNN维护了policy和value function的估计,但它没用deterministic policy。在学习过程中使用n-step回报来同时更新policy和value function。
网络结构使用了CNN,其中一个softmax output作为policy,即\(\pi(a_t|s_t;\theta)\),另一个linear output为value function,即\(V(s_t;\theta _v)\),其余layer都共享。
作者还发现一个古老的技巧,即将policy的entropy加到目标函数可以避免收敛到次优确定性解。直观上,加上该正则项后目标函数更鼓励找entropy大的,即形状“扁平”的分布,这样就不容易在训练过程中聚集到某一个动作上去。
在优化方法上,作者使用了基于RPMProp的一种变体。
ray的a3c代码:https://github.com/ray-project/ray/tree/master/python/ray/rllib/agents/a3c
3. PPO
参考业界 | OpenAI 提出强化学习近端策略优化,可替代策略梯度法
Proximal Policy Optimization Algorithms
openai的blog:https://blog.openai.com/openai-baselines-ppo/
策略梯度法(Policy gradient methods)是近来使用深度神经网络进行控制的突破基础,不论是视频游戏还是 3D 移动或者围棋控制等,它们都基于策略梯度法。但但是通过策略梯度法获得优秀的结果是十分困难的,policy gradient有以下几点不足:
- 它对步长大小的选择非常敏感。如果迭代步长太小,那么训练进展会非常慢,但如果迭代步长太大,那么信号将受到噪声的强烈干扰,因此我们会看到性能会急剧降低。
- 策略梯度法有非常低的样本效率,它需要数百万(或数十亿)的时间步骤来学习一个简单的任务。
研究人员希望能通过约束或其他优化策略更新(policy update)大小的方法来消除这些缺陷,如 TRPO 和 ACER 等方法。
- ACER(Sample Efficient Actor-Critic with Experience Replay)方法要比PPO方法复杂得多,需要额外添加代码来修正off-policy和重构缓冲器,但它在Atari基准上仅仅比PPO好一点点
- TRPO(Trust region policy optimization,置信域策略优化)虽然对连续控制任务非常有用,但它并不容易与那些在策略和值函数或辅助损失函数(auxiliary losses)间共享参数的算法兼容,即那些用于解决 Atari 和其他视觉输入很重要领域的算法。
PPO 算法很好地权衡了实现简单性、样本复杂度和调参难度,它尝试在每一迭代步计算一个更新以最小化成本函数,在计算梯度时还需要确保与先前策略有相对较小的偏差。
之前介绍过一个 PPO 变体(在NIPS2016上有一个talk Deep Reinforcement Learning Through Policy Optimization),即使用一个适应性 KL 惩罚项来控制每一次迭代中的策略改变。这次的目标函数实现了一种与随机梯度下降相匹配的置信域(Trust Region)更新方法,它同时还移除了 KL 惩罚项以简化算法和构建适应性更新。在测试中该算法在连续控制任务中取得了最好的性能,并且尽管实现起来非常简单,但它同样在 Atari 上获得了与 ACER 算法相匹配的性能。
4. rainbow
Rainbow: Combining improvements in deep reinforcement learning
参考DeepMind提出Rainbow:整合DQN算法中的六种变体
- Double DQN(DDQN;van Hasselt、Guez&Silver;2016)通过解耦选择(decoupling selection)和引导行动评估解决了Q-learning过度估计偏差的问题。
- Prioritized experience replay(Schaul 等人;2015)通过重放(replay)学习到更频繁的转换,提升了数据效率。
- dueling 网络架构(Wang 等人;2016)可以通过分别表示状态值和动作奖励来概括各种动作。
- 从多步骤引导程序目标中学习(Sutton;1988;Sutton & Barto 1998)如 A3C(Mnih 等人;2016)中使用偏差-方差权衡,而帮助将最新观察到的奖励快速传播到旧状态中。
- 分布式 Q-learning(Bellemare、Dabney & Munos;2017)学习了折扣回报(discounted returns)的分类分布(代替了估计平均值)。
- Noisy DQN(Fortunato 等人;2017)使用随机网络层进行exploration。
以上这些算法各自都可以提升 DQN 性能的某个方面,因为它们都着力于解决不同的问题,而且都构建在同一个框架上,所以能够被我们整合起来。
5. APE-X
5.1 简介
参考最前沿:当我们以为Rainbow就是Atari游戏的巅峰时,Ape-X出来把Rainbow秒成了渣!
Distributed Prioritized Experience Replay
只使用一个learner和一个Replay buffer,但是分布式的使用了多个Actor来生成数据,paper中实验使用了360个Actor(一个Actor一个CPU)。DeepMind产生专门做这个的想法主要是从Rainbow的研究中发现:Prioritization was found to be the most important ingredient contributing
to the agent’s performance.
Replay的优先级对于性能影响是最大的,而之前的Prioritised Replay Buffer只用单一Actor来采集数据,效率偏低。那么这篇文章中,加上分布式,并且让每一个Actor都不完全一样,用\(\varepsilon -greedy\)采样时的\(\varepsilon \)不一样。这样可以更好的做explore,并且更全面的寻找优先级最高的replay来训练。
- 比以前方法大得多得多的Replay Buffer,毕竟同时用几百个actor来采集数据,充分挖掘了计算资源。这个本身可以大幅度加快训练速度。
- 通过不同的Actor得到不同优先级Priority的Replay,如上面所说,大幅度提升explore的能力,防止过拟合。这是为什么Ape-X效果提升的最主要原因。
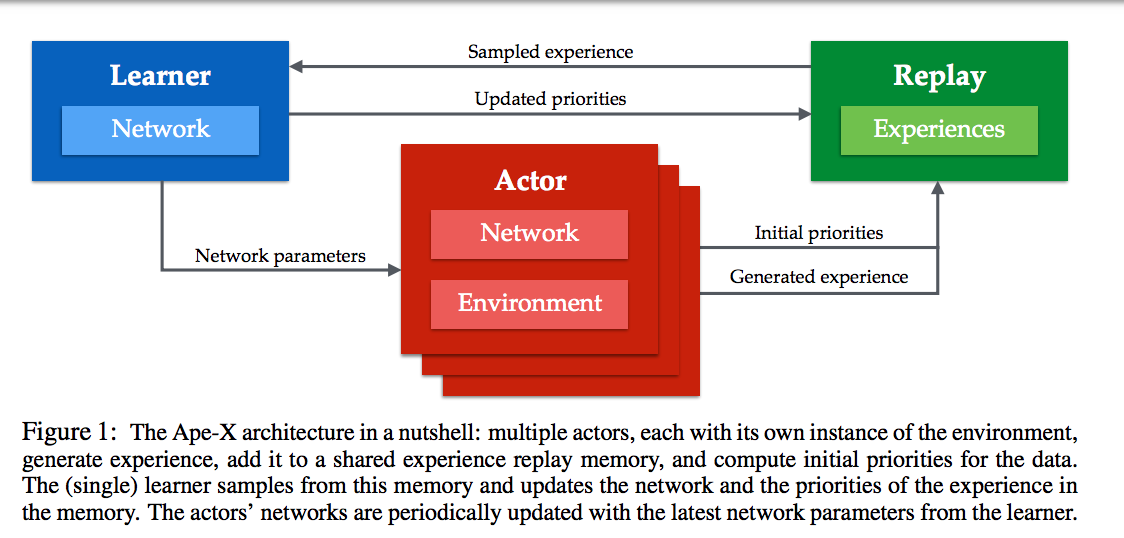
整个算法也就是训练架构上发生改变,算法实质并没有变化。同时,由于使用Replay Buffer是Off-Policy独有,因此,这篇paper就在DQN和DDPG上进行改变验证。
如上图,
- 多个actor,每个有自己的环境,并且可以产生experience,并将其写入一个共享的experience replay memory,并且能计算initial priorities
- 一个learner,从memory中sample,然后更新memory中的experience的priorities,并更新网络参数
- 每个actor的网络定期地从learner获取最新的网络参数
5.2 Actor的算法
- procedure
\(ACTOR(B, T)\)// 在environment instance中运行agent,并存储experiences
\(\theta_0\leftarrow LEARNER.PARAMETERS()\)// remote call以获取最新的网络参数\(s_0\leftarrow ENVIRONMENT.INITIALIZE() \)// 从环境中获取初始状态- for t = 1 to T do
\(a_{t-1}\leftarrow \pi \theta _{t-1}(s_{t-1})\)// 使用当前policy选择一个动作\(r_t,\gamma_t,s_t\leftarrow ENVIRONMENT.STEP(a_{t-1})\)// 在环境中执行这个动作\(LOCALBUFFER.ADD((s_{t-1},a_{t-1},r_t,\gamma_t))\)// 将data放入local buffer中- if
\(LOCALBUFFER.SIZE() \gt B\)then // 在一个后台线程中,定期地send data to replay
\(\tau \leftarrow LOCALBUFFER.GET(B)\)// 获取buffered data(例如,batch of multi-step transitions)\(p \leftarrow COMPUTEPRIORITIES(\tau)\)// 计算experience的优先级(例如,绝对TD error)\(REPLAY.ADD(\tau,p)\)// remote call以将experience加入replay memory中- endif
\(PERIODICALLY(\theta_t\leftarrow LEARNER.PARAMETERS())\)// 获取最新的网络参数- endfor
- end procedure
5.3 Learner的算法
- procedure
\(LEARNER(T)\)// 使用从memory中sampled的batches来更新网络
\(\theta_0\leftarrow INITIALIZENETWORK()\)- for t = 1 to T do // 更新参数T次
\(id,\tau \leftarrow REPLAY.SAMPLE()\)// 在后台线程中sample一个 prioritized batch的transitions\(l_t \leftarrow COMPUTELOSS(\tau;\theta_t)\)// Apply learning rule,例如double Q-learning或者DDPG\(\theta_{t+1}\leftarrow UPDATEPARAMETERS(l_t;\theta_t)\)\(p \leftarrow COMPUTEPRIORITIES()\)// 计算experience的优先级(例如,绝对TD error)【和Actor一样】\(REPLAY.SETPRIORITY(id,p)\)// remote call以更新优先级\(PERIODICALLY(REPLAY.REMOVETOFIT())\)// 从replay memory中删掉旧的experience- endfor
- end procedure
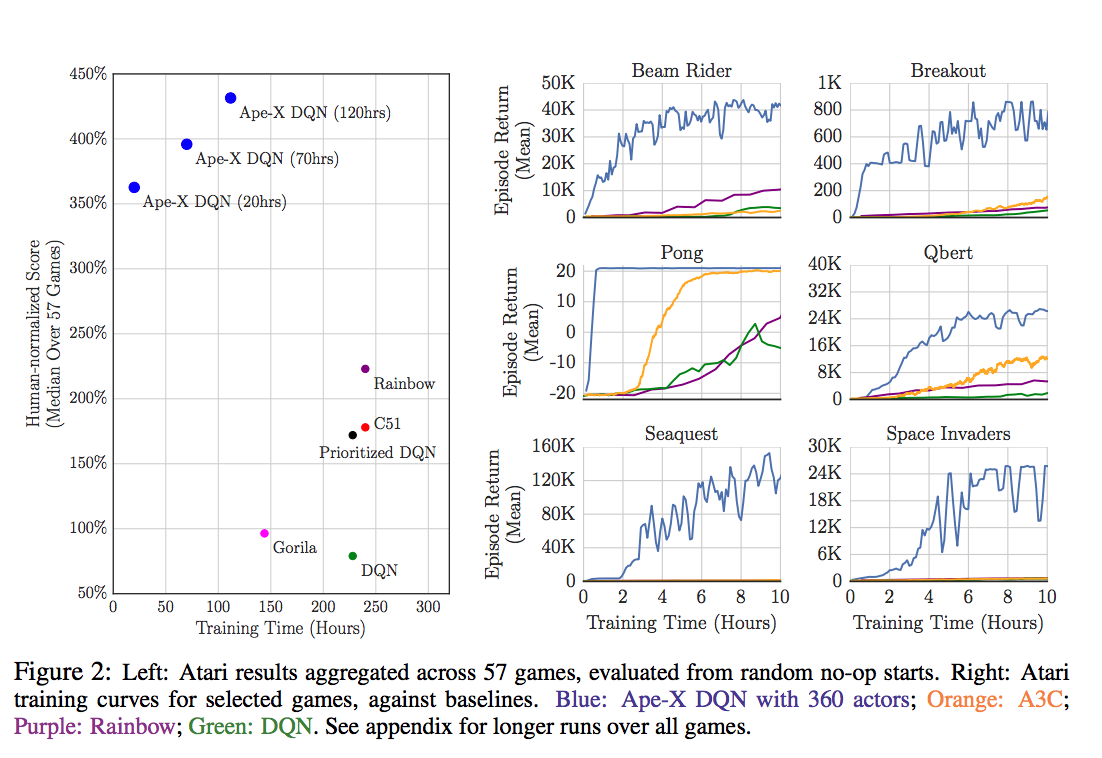
效果:
代码
ray的ape-x代码:https://github.com/ray-project/ray/blob/master/python/ray/rllib/agents/dqn/apex.py
6. rudder
参考比TD、MC、MCTS指数级快,性能超越A3C、DDQN等模型,这篇RL算法论文在Reddit上火了
在强化学习中,延迟奖励的存在会严重影响性能,主要表现在随着延迟步数的增加,对时间差分(TD)估计偏差的纠正时间的指数级增长,和蒙特卡洛(MC)估计方差的指数级增长。针对这一问题,来自奥地利约翰开普勒林茨大学 LIT AI Lab 的研究者提出了一种基于返回值分解的新方法 RUDDER。实验表明,RUDDER 的速度是 TD、MC 以及 MC 树搜索(MCTS)的指数级,并在特定 Atari 游戏的训练中很快超越 rainbow、A3C、DDQN 等多种著名强化学习模型的性能。
RUDDER: Return Decomposition for Delayed Rewards
源码:https://github.com/ml-jku/baselines-rudder
7. IMPALA
参考前沿 | DeepMind提出新型架构IMPALA:帮助实现单智能体的多任务强化学习
IMPALA 受流行的 A3C 架构的启发,A3C架构使用多个分布式actor来学习智能体的参数。在此类模型中,每个actor使用策略参数在环境中动作。actor周期性地暂停探索,和中央参数服务器共享它们计算出的梯度,用于梯度更新
IMPALA的actor不用于计算梯度,而是用于收集经验,然后传输至可计算梯度的中央学习器,生成一个具备完全独立的actor和learner的模型。为了利用现代计算系统,IMPALA可使用单个学习器或执行同步更新的多个学习器来实现。用这种方式分离学习和动作可以有效地提高整个系统的吞吐量,因为 actor不再需要等待学习步(像 batched A2C 架构中那样)。这使得我们可以在多个有趣的环境中训练IMPALA,无需经历帧渲染时间的变动或耗时的任务重启。
IMPALA: Scalable Distributed Deep-RL with Importance Weighted Actor-Learner Architectures
xx. 自己搞一下
参考一个简单的例子:强化学习异步分布式训练实现
其他RL平台
open spiel
DeepMind开源强化学习游戏框架,25款线上游戏等你来挑战
https://github.com/deepmind/open_spiel
目前大多是棋牌、博弈相关游戏。
rlpyt
https://github.com/astooke/rlpyt
集合三大类无模型强化学习算法,BAIR开源RL代码库rlpyt
rlpyt: A Research Code Base for Deep Reinforcement Learning in PyTorch
rlpyt 库的重要特征和能力包括:
- 以串行模式运行实验(对 debug 有帮助);
- 以并行模式运行实验,具备并行采样和/或多 GPU 优化的选项;
- 同步或异步采样-优化(异步模式通过 replay buffer 实现);
- 在环境采样中,使用 CPU 或 GPU 进行训练和/或分批动作选择;
- 全面支持循环智能体;
- 在训练过程中,执行在线或离线评估,以及智能体诊断日志记录;
- 在本地计算机上,启动对实验进行栈/队列(stacking / queueing)设置的程序;
- 模块化:易于修改和对已有组件的重用;
- 兼容 OpenAI Gym 环境接口。
rlpyt 库中的已实现算法包括:
- 策略梯度:A2C、PPO
- DQN及其变体:Double、Dueling、Categorical、Rainbow minus Noisy Nets、Recurrent (R2D2-style)
- QPG:DDPG、TD3、SAC
FEN
参考兼顾公平与效率?北大NeurIPS 19论文提出多智能体强化学习方法FEN
公平有助于人类社会的稳定和生产力的提高,同样对于多智能体系统也十分重要。然而让一组智能体学习提升系统效率并同时保持公平是一个复杂的、多目标的、联合策略优化问题。目前主流的多智能体强化学习算法没有考虑公平性的问题,一些针对特定情景公平性的方法又依赖专家知识,这对于一般性情景并不适用。
作者提出一种分层多智能体强化学习方法 Fair-Efficient Network(FEN,「分」),从三个方面解决这一问题:
- 提出 fair-efficient reward,用于学习效率与公平。
- 提出一种 hierarchy 架构,降低学习难度。
- 提出 FEN 的分布式训练方法。
原创文章,转载请注明出处!
本文链接:http://daiwk.github.io/posts/rl-distributed-rl.html