首页 > 强化学习 > 正文


原创文章,转载请注明出处!
本文链接:http://daiwk.github.io/posts/rl-summary.html
rl summary
标签:rl summary
2018-05-14
目录
概览
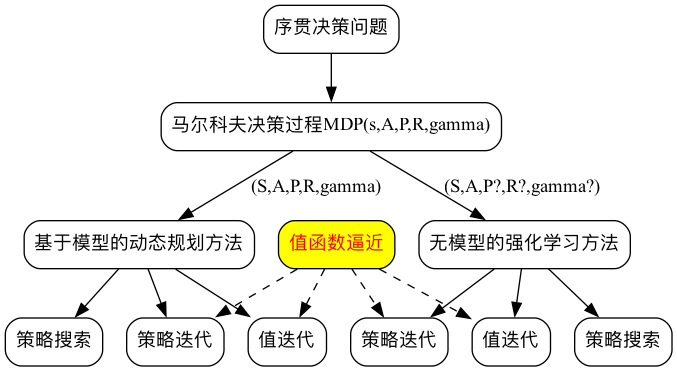
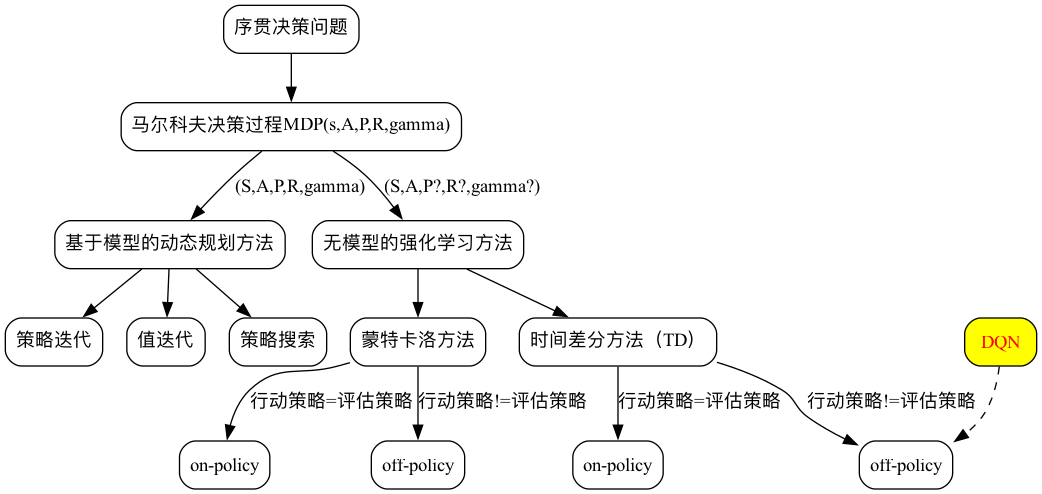
基于值函数的强化学习方法
基于值函数的方法是间接方法,即通过学习值函数(value function)或者动作值函数(action-value function)来得到policy。
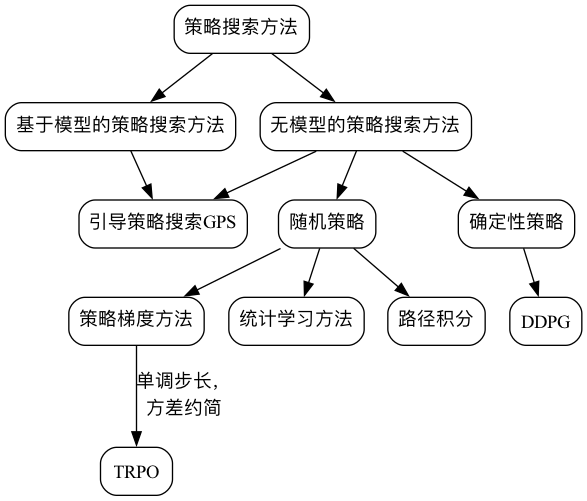
策略搜索方法
直接对policy进行建模和学习
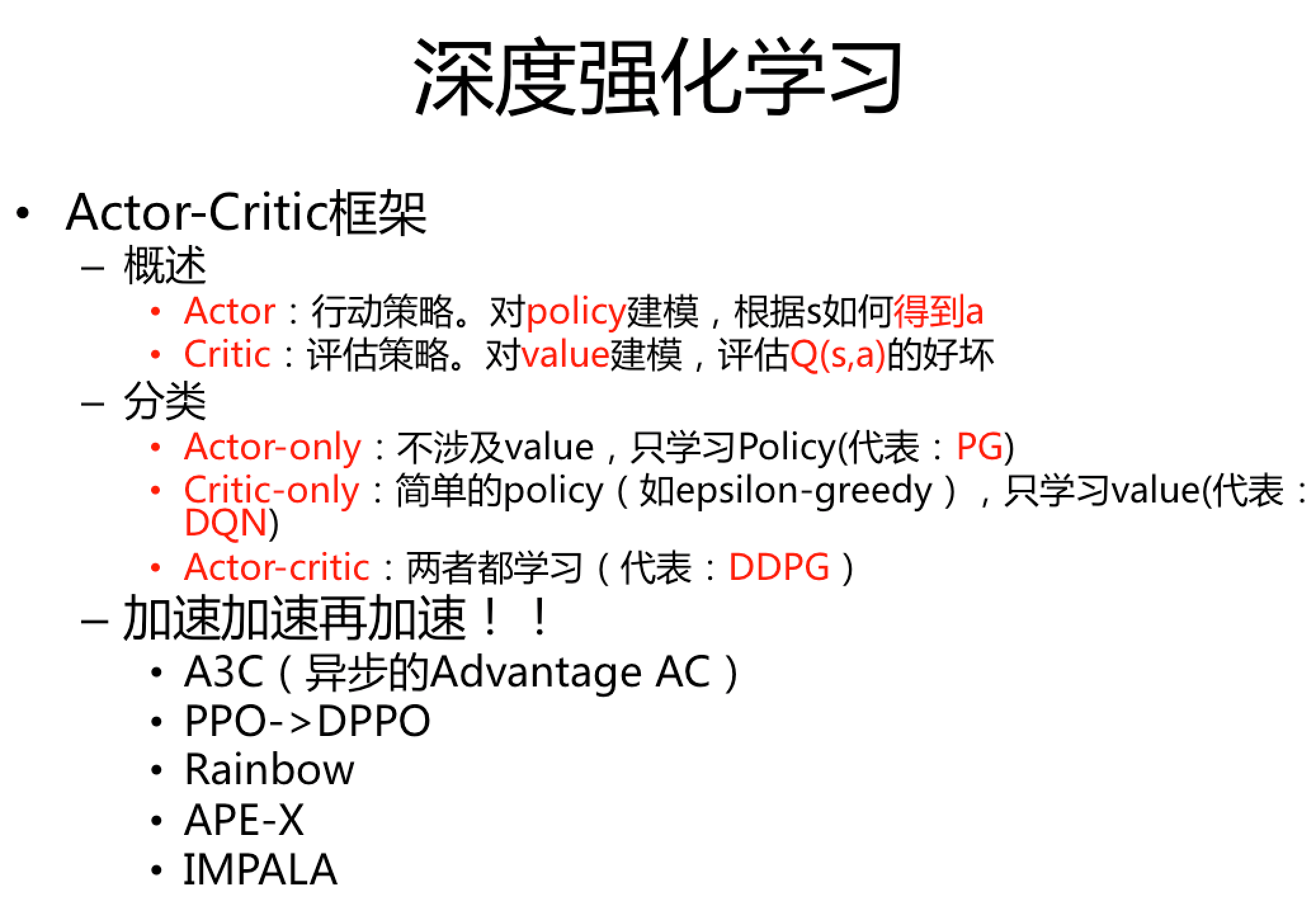
自己的小结
某个时候整理了个ppt:
原创文章,转载请注明出处!
本文链接:http://daiwk.github.io/posts/rl-summary.html
comment here..