首页 > 深度学习 > 正文
原创文章,转载请注明出处!
本文链接:http://daiwk.github.io/posts/dl-mtl.html
multi-task learning
标签:mtl, multi-task learning, 多目标
2018-04-12
目录
参考:
阿里天池的一个讲解【深度学习系列09】Multi-Task Learning for E-commerce
两大类mtl方法
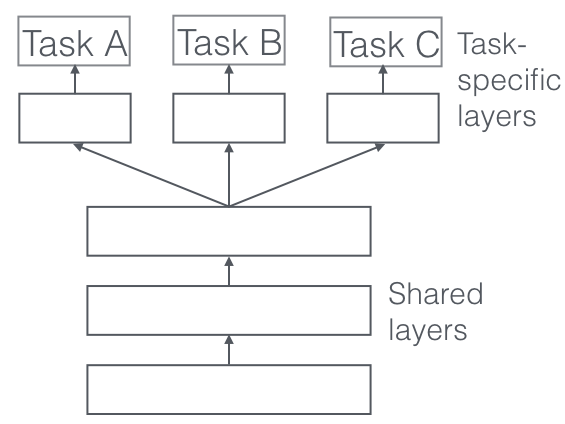
hard参数共享
所有task共享大的隐层表示,然后每个task有自己的output层。可以极大地减少过拟合,因为大的隐层表示的参数量比每个task自己的小output的参数量要大得多。
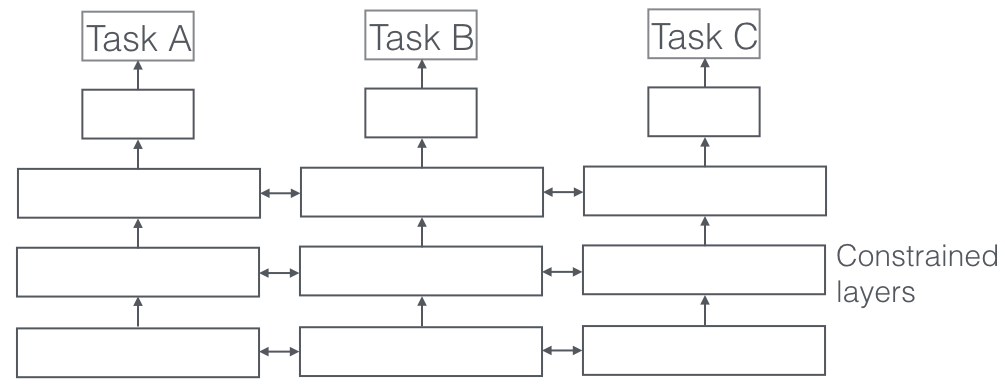
soft参数共享
每个task有自己的模型和自己的参数。模型参数间的距离一般会使用\(\ell_2\)正则进行正则化,目的是为了让参数间更相似。
mtl为什么会work
假设task A和task B,有共同的隐层表示F。
隐式数据增强
Attention focusing
Eavesdropping
Representation bias
Regularization
非神经网络中的mtl
Block-sparse regularization
Learning task relationships
MTL Deep Learning的Recent work
Deep Relationship Networks
Fully-Adaptive Feature Sharing
Cross-stitch Networks
Low supervision
A Joint Many-Task model
Weighting losses with uncertainty
Tensor factorisation for MTL
Sluice Networks
What should I share in my model?
Auxiliary tasks
Related task Adversarial Hints Focusing attention Quantization smoothing Predicting inputs Using the future to predict the present Representation learning What auxiliary tasks are helpful? Conclusion
原创文章,转载请注明出处!
本文链接:http://daiwk.github.io/posts/dl-mtl.html
comment here..