BAM
标签:BAM, born again multitask目录
论文地址:BAM! Born-Again Multi-Task Networks for Natural Language Understanding
概述
构建能够执行多个任务的单个模型一直是NLP领域的难题。多任务NLP对很多应用而言是无效的,多任务模型通常比单任务模型性能差。但是该研究提出利用知识蒸馏方法,让单任务模型高效教导多任务模型,从而在不同单任务上都有很好的表现。
知识蒸馏即将知识从「教师」模型迁移到「学生」模型,执行方式为训练学生模型模仿教师模型的预测。在Born-Again Neural Networks中,教师和学生具备同样的神经网络架构和模型大小,然而令人惊讶的是,学生网络的性能超越了教师网络。该研究将这一想法扩展到多任务模型训练环境中。
研究者使用多个变体对比Single->Multi born-again知识蒸馏,这些变体包括single->single的知识蒸馏和multi->multi的知识蒸馏,还有single->multi->single->multi。此外,该研究还提出了一个简单的教师退火(teacher annealing)方法,帮助学生模型超越教师模型,大幅改善预测结果。
模型结构
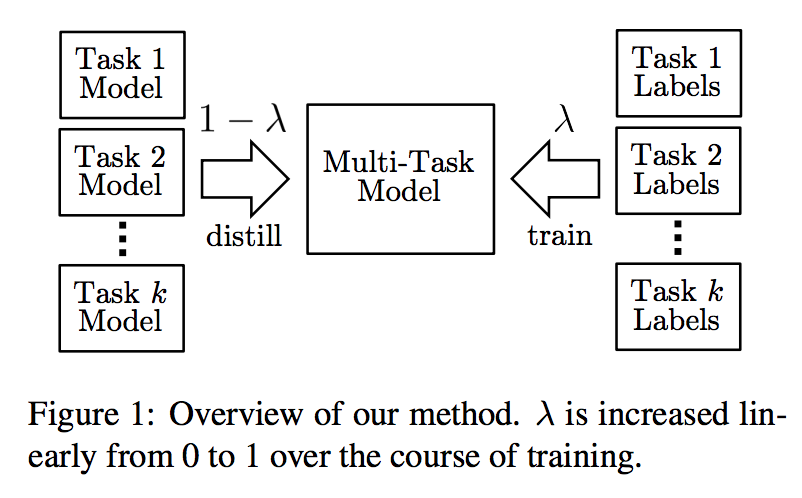
上面是整体模型的结构,其采用多个任务的单模型与对应标签作为输入。其中多任务模型主要基于BERT,因此该多任务模型能通过知识蒸馏学习到各单任务模型的语言知识。模型会有一个教师退火的过程,即最开始由多个单任务模型教多任务模型学习,而随着训练的进行,多任务模型将更多使用真实任务标签进行训练(即图中的\(\lambda\)从0慢慢变到1)。
方法
多任务训练
模型:该研究所有模型均基于BERT构建。该模型将byte-pair-tokenized的输入句子传输到Transformer网络,为每个token生成语境化的表征。最后一层的特征向量用token CLS的向量\(c\)来表示。对于分类任务,研究者使用标准softmax层直接分类,\(softmax(Wc)\)。对于回归任务,接一个size是1的nn并使用sigmoid激活函数,\(sigmoid(w^Tc)\)。在该研究开发的多任务模型中,除了基于BERT的分类器,所有模型参数在所有任务上共享,这意味着不到 0.01% 的参数是task-specific的。和BERT一样,字符级词嵌入和Transformer使用「masked LM」预训练阶段的权重进行初始化。
训练:单任务训练按照BERT原文的研究来执行。至于多任务训练,研究者将打乱不同任务的顺序,即使在小批量内也会进行shuffle。最后模型的训练为最小化所有任务上的(未加权)损失和。
知识蒸馏
使用知识蒸馏方法,让单任务模型来教多任务模型。这里学生网络和教师网络具备同样的模型架构。
知识蒸馏中学生网络要模仿教师网络,这有可能导致学生网络受限于教师网络的性能,无法超过教师网络。为了解决该问题,该研究提出teacher annealing,在训练过程中混合教师预测和gold label。
原创文章,转载请注明出处!
本文链接:http://daiwk.github.io/posts/nlp-bam.html