首页 > 自然语言处理 > 正文
原创文章,转载请注明出处!
本文链接:http://daiwk.github.io/posts/nlp-paddle-lark.html
paddle的LARK(ERNIE/BERT等)+bert的各种变种
标签:paddle, bert, lark, ernie, tinybert, vlbert, vl-bert, vilbert, xlm, laser, mass, unilm, roberta, sensebert, faster transformer, 数字
2019-03-20
小结
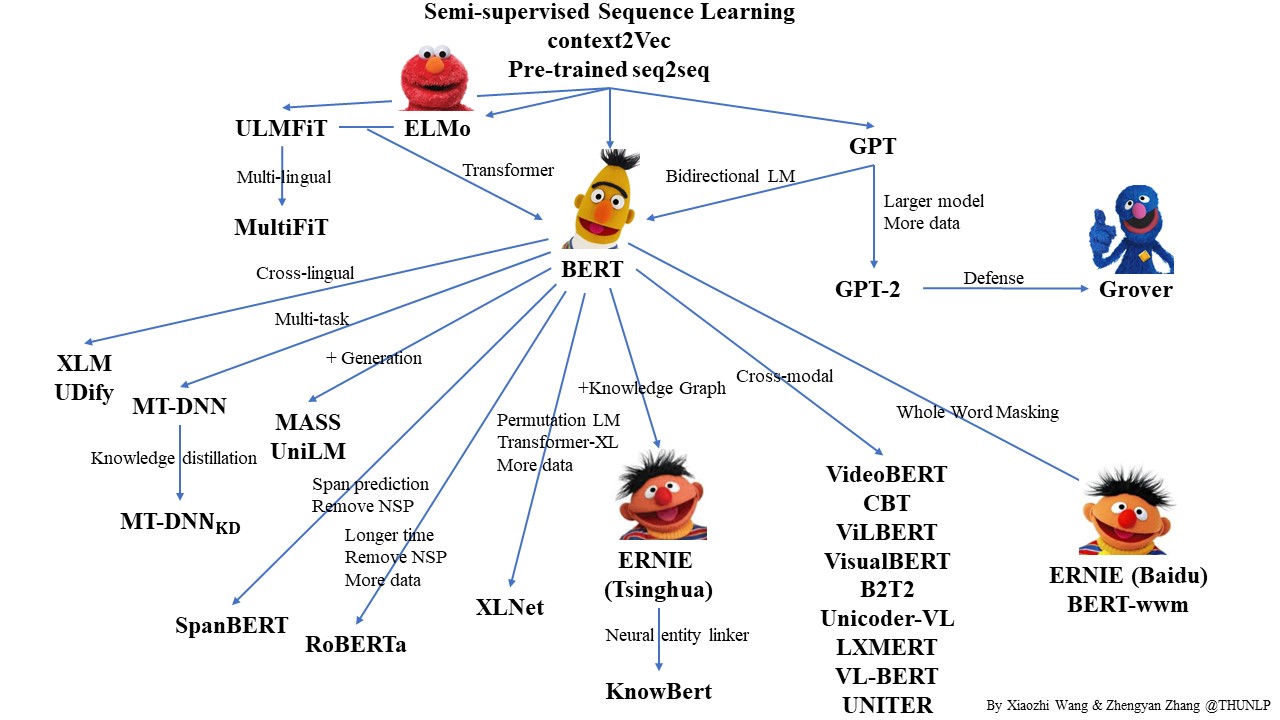
https://github.com/thunlp/PLMpapers
paddle的LARK里包含了一些nlp模型
bert
finetune和跑预测并save模型
BERT_BASE_PATH=./pretrained_model/chinese_L-12_H-768_A-12/
TASK_NAME="XNLI"
#DATA_PATH=./data/XNLI-1.0-demo/
DATA_PATH=./data/XNLI-MT-1.0-dwk/
INIT_CKPT_PATH=./output/step_50
SAVE_INFERENCE_PATH=./output/infer_step_50 ## 这个目录下会有个__model__文件,给在线infer用的,注意paddle的版本要用1.3.1以上的,1.3.0生成的这个目录有bug
python=../../python-2.7.14-paddle-1.3.1/bin/python
export FLAGS_enable_parallel_graph=1
export FLAGS_sync_nccl_allreduce=1
export CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7
export CPU_NUM=3 ## 设置跑的cpu核数
TASK_NAME='XNLI'
CKPT_PATH=./output/
function finetune_xnli()
{
### 如果有56核的cpu,会占114g。。;而如果是12核的cpu,只会占25g内存
DATA_PATH=./data/XNLI-MT-1.0-dwk/
$python -u run_classifier.py --task_name ${TASK_NAME} \
--use_cuda false \
--do_train true \
--do_val true \
--do_test true \
--batch_size 1 \
--in_tokens false \
--init_pretraining_params ${BERT_BASE_PATH}/params \
--data_dir ${DATA_PATH} \
--vocab_path ${BERT_BASE_PATH}/vocab.txt \
--checkpoints ${CKPT_PATH} \
--save_steps 50 \
--weight_decay 0.01 \
--warmup_proportion 0.0 \
--validation_steps 2500 \
--epoch 1 \
--max_seq_len 8 \
--bert_config_path ${BERT_BASE_PATH}/bert_config.json \
--learning_rate 1e-4 \
--skip_steps 1 \
--random_seed 1
}
function save_inference_model()
{
### 如果是56核cpu,会占22g内存..
DATA_PATH=./data/XNLI-1.0-demo/
$python -u predict_classifier.py --task_name ${TASK_NAME} \
--use_cuda false \
--batch_size 1 \
--data_dir ${DATA_PATH} \
--vocab_path ${BERT_BASE_PATH}/vocab.txt \
--do_lower_case true \
--init_checkpoint ${INIT_CKPT_PATH} \
--max_seq_len 8 \
--bert_config_path ${BERT_BASE_PATH}/bert_config.json \
--do_predict true \
--save_inference_model_path ${SAVE_INFERENCE_PATH}
}
function main()
{
finetune_xnli
[[ $? -ne 0 ]] && exit 1
save_inference_model
[[ $? -ne 0 ]] && exit 1
return 0
}
main 2>&1
线上infer部分
参考这个readme:
生成demo文件可以参考
TASK_NAME="xnli"
DATA_PATH=../data/XNLI-1.0/
BERT_BASE_PATH=../pretrained_model/chinese_L-12_H-768_A-12/
python=../../../python-2.7.14-paddle-1.3.1/bin/python
$python gen_demo_data.py \
--task_name ${TASK_NAME} \
--data_path ${DATA_PATH} \
--vocab_path "${BERT_BASE_PATH}/vocab.txt" \
--batch_size 1 \
> bert_data.demo
# --in_tokens \
运行示例:
INFERENCE_MODEL_PATH=./output/infer_step_50
DATA_PATH=./bert_data.demo
REPEAT_TIMES=1
./bin/bert_demo --logtostderr \
--model_dir $INFERENCE_MODEL_PATH \
--data $DATA_PATH \
--repeat $REPEAT_TIMES \
--output_prediction
原创文章,转载请注明出处!
本文链接:http://daiwk.github.io/posts/nlp-paddle-lark.html
comment here..