首页 > 常用平台 > 正文
原创文章,转载请注明出处!
本文链接:http://daiwk.github.io/posts/platform-paddle-fluid.html
paddle fluid
标签:paddle, fluid
2018-03-28
目录
简介
参考https://daiwk.github.io/posts/platform-tensorflow-folding.html
先了解下eager execution的优点:
- 快速调试即刻的运行错误并通过 Python 工具进行整合
- 借助易于使用的 Python 控制流支持动态模型
- 为自定义和高阶梯度提供强大支持
- 适用于几乎所有可用的 TensorFlow 运算
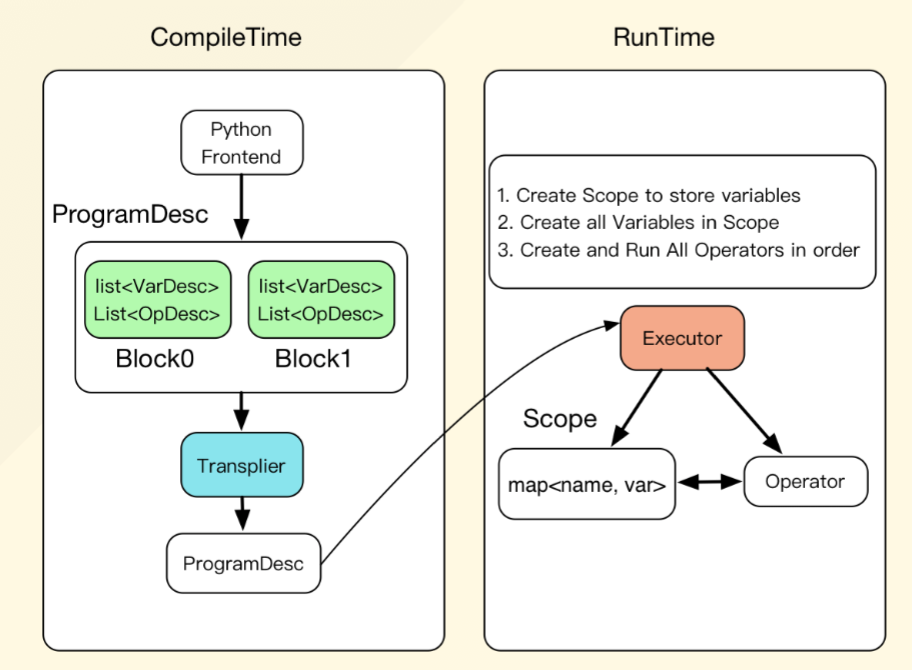
fluid也有点类似,分为编译时和运行时。
编译时:
- 创建变量描述Variable
- 创建operators的描述OpDesc
- 创建operator的属性
- 推断变量的类型和形状,进行静态检查:InferShape
- 规划变量的内存复用
- 创建反向计算
- 添加优化相关的Operators
- (可选)添加多卡/多机相关的Operator,生成在多卡/多机上运行的程序
运行时:
- 创建Executor
- 为将要执行的一段计算,在层级式的Scope空间中创建Scope
- 创建Block,依次执行Block
另外,fluid自己封装了各种switch/ifelse/while_op等。
核心概念
编译时概念
program就是一个nn的训练/预测任务,由多个可嵌套的Block组成,而每个Block中包含了Variable和Operator:
VarDesc + TensorDesc + OpDesc ==> BlockDesc ==> ProgramDesc
transpiler将一个ProgramDesc转成另一个ProgramDesc,有以下两种:
- Memory optimization transpiler: 在原始ProgramDesc中插入FreeMemoryOps,在一次迭代结束前提前释放内存,使得能够维持较小的memory footprint
- distributed training transpiler: 将原始ProgramDesc转化为对应的分布式版本,包括:
- trainer进程执行的ProgramDesc
- parameter server执行的ProgramDesc
WIP: 输入ProgramDesc,生成可以直接被gcc/nvcc/icc等编译的代码,编译得到可执行文件。
例如:
x = fluid.layers.data(name='x', shape=[13], dtype='float32')
y_predict = fluid.layers.fc(input=x, size=1, act=None)
y = fluid.layers.data(name='y', shape=[1], dtype='float32')
cost = fluid.layers.square_error_cost(input=y_predict, label=y)
avg_cost = fluid.layers.mean(cost)
sgd_optimizer = fluid.optimizer.SGD(learning_rate=0.001)
optimize_ops, params_grads = sgd_optimizer.minimize(avg_cost)
use_cuda = False
place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
training_role = os.getenv("TRAINING_ROLE", "TRAINER")
if training_role == "PSERVER":
place = fluid.CPUPlace()
exe = fluid.Executor(place)
这个时候可以打出来:
>>> print fluid.default_startup_program().to_string(True)
blocks {
idx: 0
parent_idx: -1
vars {
name: "learning_rate_0"
type {
type: LOD_TENSOR
lod_tensor {
tensor {
data_type: FP32
dims: 1
}
}
}
persistable: true
}
vars {
name: "fc_0.b_0"
type {
type: LOD_TENSOR
lod_tensor {
tensor {
data_type: FP32
dims: 1
}
}
}
persistable: true
}
vars {
name: "fc_0.w_0"
type {
type: LOD_TENSOR
lod_tensor {
tensor {
data_type: FP32
dims: 13
dims: 1
}
}
}
persistable: true
}
ops {
outputs {
parameter: "Out"
arguments: "learning_rate_0"
}
type: "fill_constant"
attrs {
name: "op_role_var"
type: STRINGS
}
attrs {
name: "op_role"
type: INT
i: 0
}
attrs {
name: "force_cpu"
type: BOOLEAN
b: false
}
attrs {
name: "value"
type: FLOAT
f: 0.0010000000475
}
attrs {
name: "shape"
type: INTS
ints: 1
}
attrs {
name: "dtype"
type: INT
i: 5
}
}
ops {
outputs {
parameter: "Out"
arguments: "fc_0.b_0"
}
type: "fill_constant"
attrs {
name: "op_role_var"
type: STRINGS
}
attrs {
name: "op_role"
type: INT
i: 0
}
attrs {
name: "force_cpu"
type: BOOLEAN
b: false
}
attrs {
name: "value"
type: FLOAT
f: 0.0
}
attrs {
name: "shape"
type: INTS
ints: 1
}
attrs {
name: "dtype"
type: INT
i: 5
}
}
ops {
outputs {
parameter: "Out"
arguments: "fc_0.w_0"
}
type: "uniform_random"
attrs {
name: "op_role_var"
type: STRINGS
}
attrs {
name: "op_role"
type: INT
i: 0
}
attrs {
name: "dtype"
type: INT
i: 5
}
attrs {
name: "seed"
type: INT
i: 0
}
attrs {
name: "min"
type: FLOAT
f: -0.654653668404
}
attrs {
name: "max"
type: FLOAT
f: 0.654653668404
}
attrs {
name: "shape"
type: INTS
ints: 13
ints: 1
}
}
}
再接下来,可以打出更多的信息(会发现多了梯度等):
>>> print fluid.default_main_program().to_string(True)
...
}
}
}
persistable: true
}
vars {
name: "fc_0.tmp_1"
type {
type: LOD_TENSOR
lod_tensor {
tensor {
data_type: FP32
dims: -1
dims: 1
}
lod_level: 0
}
}
persistable: false
}
vars {
name: "square_error_cost_0.tmp_0"
type {
type: LOD_TENSOR
lod_tensor {
tensor {
data_type: FP32
dims: -1
dims: 1
}
lod_level: 0
}
}
persistable: false
}
vars {
name: "learning_rate_0"
type {
type: LOD_TENSOR
lod_tensor {
tensor {
data_type: FP32
dims: 1
}
}
}
persistable: true
}
vars {
name: "fc_0.tmp_0@GRAD"
type {
type: LOD_TENSOR
lod_tensor {
tensor {
data_type: FP32
dims: -1
dims: 1
}
}
}
}
vars {
name: "fc_0.tmp_1@GRAD"
type {
type: LOD_TENSOR
lod_tensor {
tensor {
data_type: FP32
dims: -1
dims: 1
}
}
}
}
vars {
name: "square_error_cost_0.tmp_1"
type {
type: LOD_TENSOR
lod_tensor {
tensor {
data_type: FP32
dims: -1
dims: 1
}
lod_level: 0
}
}
persistable: false
}
vars {
name: "mean_0.tmp_0@GRAD"
type {
type: LOD_TENSOR
lod_tensor {
tensor {
data_type: FP32
dims: 1
}
}
}
persistable: true
}
ops {
inputs {
parameter: "X"
arguments: "x"
}
inputs {
parameter: "Y"
arguments: "fc_0.w_0"
}
outputs {
parameter: "Out"
arguments: "fc_0.tmp_0"
}
type: "mul"
attrs {
name: "op_role_var"
type: STRINGS
}
attrs {
name: "op_role"
type: INT
i: 0
}
attrs {
name: "y_num_col_dims"
type: INT
i: 1
}
attrs {
name: "x_num_col_dims"
type: INT
i: 1
}
}
ops {
inputs {
parameter: "X"
arguments: "fc_0.tmp_0"
}
inputs {
parameter: "Y"
arguments: "fc_0.b_0"
}
outputs {
parameter: "Out"
arguments: "fc_0.tmp_1"
}
type: "elementwise_add"
attrs {
name: "op_role_var"
type: STRINGS
}
attrs {
name: "use_mkldnn"
type: BOOLEAN
b: false
}
attrs {
name: "op_role"
type: INT
i: 0
}
attrs {
name: "axis"
type: INT
i: 1
}
}
ops {
inputs {
parameter: "X"
arguments: "fc_0.tmp_1"
}
inputs {
parameter: "Y"
arguments: "y"
}
outputs {
parameter: "Out"
arguments: "square_error_cost_0.tmp_0"
}
type: "elementwise_sub"
attrs {
name: "op_role_var"
type: STRINGS
}
attrs {
name: "use_mkldnn"
type: BOOLEAN
b: false
}
attrs {
name: "axis"
type: INT
i: -1
}
attrs {
name: "op_role"
type: INT
i: 0
}
}
ops {
inputs {
parameter: "X"
arguments: "square_error_cost_0.tmp_0"
}
outputs {
parameter: "Out"
arguments: "square_error_cost_0.tmp_1"
}
type: "square"
attrs {
name: "op_role_var"
type: STRINGS
}
attrs {
name: "use_mkldnn"
type: BOOLEAN
b: false
}
attrs {
name: "op_role"
type: INT
i: 0
}
}
ops {
inputs {
parameter: "X"
arguments: "square_error_cost_0.tmp_1"
}
outputs {
parameter: "Out"
arguments: "mean_0.tmp_0"
}
type: "mean"
attrs {
name: "op_role_var"
type: STRINGS
}
attrs {
name: "op_role"
type: INT
i: 256
}
}
ops {
outputs {
parameter: "Out"
arguments: "mean_0.tmp_0@GRAD"
}
type: "fill_constant"
attrs {
name: "op_role"
type: INT
i: 257
}
attrs {
name: "value"
type: FLOAT
f: 1.0
}
attrs {
name: "force_cpu"
type: INT
i: 0
}
attrs {
name: "shape"
type: INTS
ints: 1
}
attrs {
name: "dtype"
type: INT
i: 5
}
}
ops {
inputs {
parameter: "Out@GRAD"
arguments: "mean_0.tmp_0@GRAD"
}
inputs {
parameter: "X"
arguments: "square_error_cost_0.tmp_1"
}
outputs {
parameter: "X@GRAD"
arguments: "square_error_cost_0.tmp_1@GRAD"
}
type: "mean_grad"
attrs {
name: "op_role"
type: INT
i: 1
}
}
ops {
inputs {
parameter: "Out"
arguments: "square_error_cost_0.tmp_1"
}
inputs {
parameter: "Out@GRAD"
arguments: "square_error_cost_0.tmp_1@GRAD"
}
inputs {
parameter: "X"
arguments: "square_error_cost_0.tmp_0"
}
outputs {
parameter: "X@GRAD"
arguments: "square_error_cost_0.tmp_0@GRAD"
}
type: "square_grad"
attrs {
name: "op_role_var"
type: STRINGS
}
attrs {
name: "use_mkldnn"
type: BOOLEAN
b: false
}
attrs {
name: "op_role"
type: INT
i: 1
}
}
ops {
inputs {
parameter: "Out"
arguments: "square_error_cost_0.tmp_0"
}
inputs {
parameter: "Out@GRAD"
arguments: "square_error_cost_0.tmp_0@GRAD"
}
inputs {
parameter: "X"
arguments: "fc_0.tmp_1"
}
inputs {
parameter: "Y"
arguments: "y"
}
outputs {
parameter: "X@GRAD"
arguments: "fc_0.tmp_1@GRAD"
}
outputs {
parameter: "Y@GRAD"
}
type: "elementwise_sub_grad"
attrs {
name: "op_role_var"
type: STRINGS
}
attrs {
name: "use_mkldnn"
type: BOOLEAN
b: false
}
attrs {
name: "axis"
type: INT
i: -1
}
attrs {
name: "op_role"
type: INT
i: 1
}
}
ops {
inputs {
parameter: "Out"
arguments: "fc_0.tmp_1"
}
inputs {
parameter: "Out@GRAD"
arguments: "fc_0.tmp_1@GRAD"
}
inputs {
parameter: "X"
arguments: "fc_0.tmp_0"
}
inputs {
parameter: "Y"
arguments: "fc_0.b_0"
}
outputs {
parameter: "X@GRAD"
arguments: "fc_0.tmp_0@GRAD"
}
outputs {
parameter: "Y@GRAD"
arguments: "fc_0.b_0@GRAD"
}
type: "elementwise_add_grad"
attrs {
name: "op_role_var"
type: STRINGS
strings: "fc_0.b_0"
strings: "fc_0.b_0@GRAD"
}
attrs {
name: "use_mkldnn"
type: BOOLEAN
b: false
}
attrs {
name: "op_role"
type: INT
i: 1
}
attrs {
name: "axis"
type: INT
i: 1
}
}
ops {
inputs {
parameter: "Out"
arguments: "fc_0.tmp_0"
}
inputs {
parameter: "Out@GRAD"
arguments: "fc_0.tmp_0@GRAD"
}
inputs {
parameter: "X"
arguments: "x"
}
inputs {
parameter: "Y"
arguments: "fc_0.w_0"
}
outputs {
parameter: "X@GRAD"
}
outputs {
parameter: "Y@GRAD"
arguments: "fc_0.w_0@GRAD"
}
type: "mul_grad"
attrs {
name: "op_role_var"
type: STRINGS
strings: "fc_0.w_0"
strings: "fc_0.w_0@GRAD"
}
attrs {
name: "op_role"
type: INT
i: 1
}
attrs {
name: "y_num_col_dims"
type: INT
i: 1
}
attrs {
name: "x_num_col_dims"
type: INT
i: 1
}
}
ops {
inputs {
parameter: "Grad"
arguments: "fc_0.b_0@GRAD"
}
inputs {
parameter: "LearningRate"
arguments: "learning_rate_0"
}
inputs {
parameter: "Param"
arguments: "fc_0.b_0"
}
outputs {
parameter: "ParamOut"
arguments: "fc_0.b_0"
}
type: "sgd"
attrs {
name: "op_role_var"
type: STRINGS
strings: "fc_0.b_0"
strings: "fc_0.b_0@GRAD"
}
attrs {
name: "op_role"
type: INT
i: 2
}
}
ops {
inputs {
parameter: "Grad"
arguments: "fc_0.w_0@GRAD"
}
inputs {
parameter: "LearningRate"
arguments: "learning_rate_0"
}
inputs {
parameter: "Param"
arguments: "fc_0.w_0"
}
outputs {
parameter: "ParamOut"
arguments: "fc_0.w_0"
}
type: "sgd"
attrs {
name: "op_role_var"
type: STRINGS
strings: "fc_0.w_0"
strings: "fc_0.w_0@GRAD"
}
attrs {
name: "op_role"
type: INT
i: 2
}
}
}
还可以用debugger模块:
>>> from paddle.fluid import debugger
>>> from paddle.fluid import framework
>>> print debugger.pprint_program_codes(framework.default_main_program())
// block-0 parent--1
// variables
Tensor x (tensor(type=float32, shape=[-1L, 13L]))
Tensor fc_0.w_0 (tensor(type=float32, shape=[13L, 1L]))
Tensor mean_0.tmp_0 (tensor(type=float32, shape=[1L]))
Tensor y (tensor(type=float32, shape=[-1L, 1L]))
Tensor fc_0.tmp_0 (tensor(type=float32, shape=[-1L, 1L]))
Tensor fc_0.b_0 (tensor(type=float32, shape=[1L]))
Tensor fc_0.tmp_1 (tensor(type=float32, shape=[-1L, 1L]))
Tensor square_error_cost_0.tmp_0 (tensor(type=float32, shape=[-1L, 1L]))
Tensor learning_rate_0 (tensor(type=float32, shape=[1L]))
Tensor square_error_cost_0.tmp_1 (tensor(type=float32, shape=[-1L, 1L]))
// operators
fc_0.tmp_0 = mul(X=x, Y=fc_0.w_0) [{op_role_var=[],op_role=0,y_num_col_dims=1,x_num_col_dims=1}]
fc_0.tmp_1 = elementwise_add(X=fc_0.tmp_0, Y=fc_0.b_0) [{op_role_var=[],use_mkldnn=False,op_role=0,axis=1}]
square_error_cost_0.tmp_0 = elementwise_sub(X=fc_0.tmp_1, Y=y) [{op_role_var=[],use_mkldnn=False,axis=-1,op_role=0}]
ymean_0.tmp_0 = mean(X=square_error_cost_0.tmp_1) [{op_role_var=[],op_role=256}]
运行时概念
- 数据相关:
- Tensor/LoDtensor/Variable
- Scope
- 计算相关:
- Block
- Kernel/OpWithKernel/OpWithoutKernel
- 执行相关:Executor
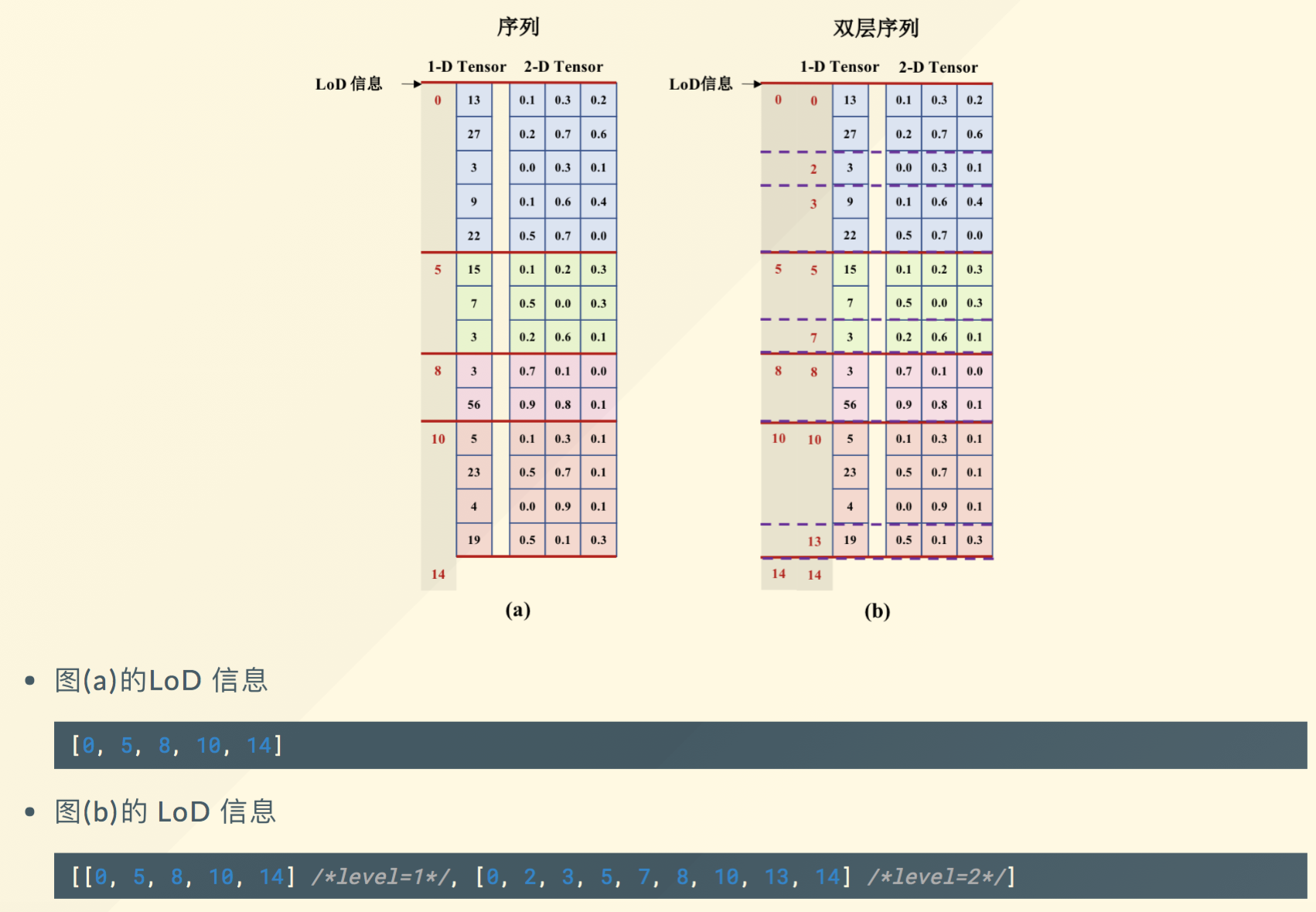
Tensor/LoD(Level-of-Detail)Tensor
Tensor是n维array的推广,LoDTensor是在Tensor基础上加了序列信息
Fluid中输入、输出以及所有可学习参数都用LodTensor表示
一个mini-batch的输入数据是一个LoDTensor:
- rnn处理变长序列不需要padding
- LoD可以理解为
vector<vector<int>> - 对于非序列数据,LoD信息为空
图中,
demo
定义以下训练流程:
def train_loop(main_program):
"""
train_loop
"""
train_reader = paddle.batch(
paddle.reader.shuffle(
cluster_data_reader(cluster_train_dir), buf_size = 500),
batch_size = BATCH_SIZE)
feeder = fluid.DataFeeder(place=place, feed_list=[x, y])
exe.run(fluid.default_startup_program())
batch_id = 0
PASS_NUM = 100
for pass_id in range(PASS_NUM):
for data in train_reader():
avg_loss_value, = exe.run(main_program,
feed=feeder.feed(data),
fetch_list=[avg_cost])
print(avg_loss_value)
visualdl.show_fluid_trend('epoch', \
pass_id, batch_id, '{\"avg_loss\":%d}' % (avg_loss_value[0]))
batch_id += 1
if avg_loss_value[0] < 10.0:
if save_dirname is not None:
fluid.io.save_inference_model(save_dirname, ['x'],
[y_predict], exe)
return
if math.isnan(float(avg_loss_value)):
sys.exit("got NaN loss, training failed.")
visualdl.show_fluid_trend('batch', \
pass_id, '{\"avg_loss\":%d}' % (avg_loss_value[0]))
if save_dirname is not None:
fluid.io.save_inference_model(save_dirname, ['x'], [y_predict], exe) def train_loop(main_program):
"""
train_loop
"""
train_reader = paddle.batch(
paddle.reader.shuffle(
cluster_data_reader(cluster_train_dir), buf_size = 500),
batch_size = BATCH_SIZE)
feeder = fluid.DataFeeder(place=place, feed_list=[x, y])
exe.run(fluid.default_startup_program())
batch_id = 0
PASS_NUM = 100
for pass_id in range(PASS_NUM):
for data in train_reader():
avg_loss_value, = exe.run(main_program,
feed=feeder.feed(data),
fetch_list=[avg_cost])
print(avg_loss_value)
visualdl.show_fluid_trend('epoch', \
pass_id, batch_id, '{\"avg_loss\":%d}' % (avg_loss_value[0]))
batch_id += 1
if avg_loss_value[0] < 10.0:
if save_dirname is not None:
fluid.io.save_inference_model(save_dirname, ['x'],
[y_predict], exe)
return
if math.isnan(float(avg_loss_value)):
sys.exit("got NaN loss, training failed.")
visualdl.show_fluid_trend('batch', \
pass_id, '{\"avg_loss\":%d}' % (avg_loss_value[0]))
if save_dirname is not None:
fluid.io.save_inference_model(save_dirname, ['x'], [y_predict], exe)
如果是local,直接调用上面的函数
train_loop(fluid.default_main_program())
如果是分布式:
port = os.getenv("PADDLE_PORT", "6174")
pserver_ips = os.getenv("PADDLE_PSERVERS") # ip,ip...
eplist = []
for ip in pserver_ips.split(","):
eplist.append(':'.join([ip, port]))
pserver_endpoints = ",".join(eplist) # ip:port,ip:port...
trainers = int(os.getenv("PADDLE_TRAINERS_NUM", "0"))
current_endpoint = os.getenv("POD_IP") + ":" + port
trainer_id = int(os.getenv("PADDLE_TRAINER_ID", "0"))
t = fluid.DistributeTranspiler()
t.transpile(
optimize_ops,
params_grads,
trainer_id,
pservers=pserver_endpoints,
trainers=trainers)
if training_role == "PSERVER":
pserver_prog = t.get_pserver_program(current_endpoint)
pserver_startup = t.get_startup_program(current_endpoint,
pserver_prog)
exe.run(pserver_startup)
exe.run(pserver_prog)
elif training_role == "TRAINER":
train_loop(t.get_trainer_program())
完整的logistic regression的demo: https://github.com/PaddlePaddle/Paddle/blob/develop/python/paddle/fluid/tests/book/test_fit_a_line.py
原创文章,转载请注明出处!
本文链接:http://daiwk.github.io/posts/platform-paddle-fluid.html
上篇:
paddle fluid分布式cpu相关
下篇:
protobufrpc
comment here..